因子(zǐ)分(fēn)析法構建景氣指數模型的探討(tǎo)
2006/2/6 10:51:15
作(zuò)者:李四争
在市(shì)場(chǎng)調研中,我們經常需要向客戶提供該公司運營狀況及其所在行業整體(tǐ)運行情況等宏觀信息,單純靠财務(wù)分(fēn)析及引用國家行業景氣指數已不能(néng)滿足客戶的需求,景氣分(fēn)析的重要性日益突出。
景氣分(fēn)析又稱為(wèi)商(shāng)業周期分(fēn)析,主要利用月(yuè)(yuè)度或季度經濟統計序列數據構建一(yī)個(gè)景氣指數,用以分(fēn)析和判斷經濟發展周期性波動所處的階段(擴張階段還是收縮階段、峰點谷點還是景氣轉折點),找出景氣狀态發生(shēng)變動的原因,預測未來(lái)經濟景氣走向,驗證和評價政策實施的效果等。
本文通過因子(zǐ)分(fēn)析法構建了(le)一(yī)個(gè)簡單的景氣指數模型,該模型适用于行業景氣及企業運營狀況(行業景氣的微觀版)方面的簡單分(fēn)析。需要注意的是,在做不同分(fēn)析時(shí)指标應做相應的修整。另外,從以下(xià)文中指标的選擇上(shàng)可以判斷該指數為(wèi)一(yī)緻合成指數,要做更進一(yī)步的分(fēn)析還需先行指數、滞後指數的支持。
一(yī)、構建前期工作(zuò)
(一(yī))充分(fēn)了(le)解影響景氣的主要因素
影響景氣的因素一(yī)般可分(fēn)為(wèi)内外兩種:外部因素主要包括國際形勢、宏觀政策、宏觀經濟指标、經濟周期、上(shàng)下(xià)遊産業鏈的供應需求變動等;内部因素主要為(wèi)産品的需求變動、生(shēng)産能(néng)力變動、技術水平變化(huà)、人(rén)力資源改善及産業政策的變化(huà)等。
(二)選用适合的指标
景氣分(fēn)析的常用指标可分(fēn)為(wèi)兩級:一(yī)級指标是影響景氣的重要因素,二級指标是其細分(fēn)的結果。一(yī)般的常用指标如(rú)下(xià):
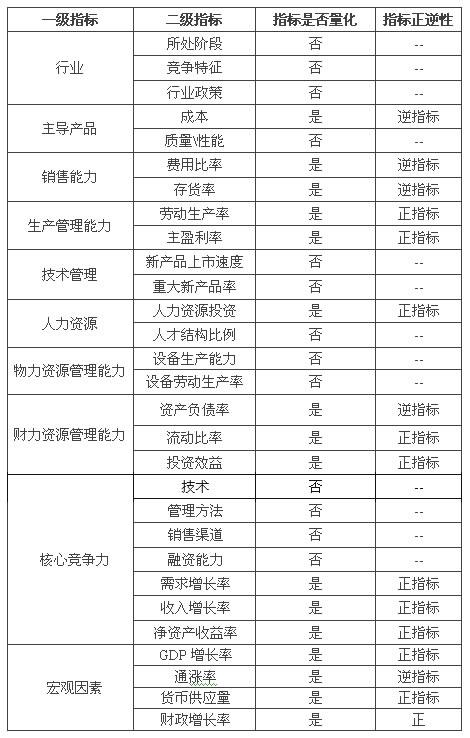
以上(shàng)指标均為(wèi)通用指标,在具體(tǐ)構建某一(yī)景氣指數時(shí)應依據實際情況增減相關(guān)指标。
(三)數據預處理(lǐ)
1、異常數據的處理(lǐ)
異常數據是指觀測數據的過大或過小的值。異常數據可能(néng)隻是數據中内在的随機變異性的一(yī)種極端的表現(xiàn),也(yě)可能(néng)是因為(wèi)實驗過程中出現(xiàn)的操作(zuò)失誤或條件改變所緻。對于前一(yī)種異常數據,必須給予保留并與其他數據一(yī)起參與統計過程。對于後一(yī)種數據,必須舍棄或修正。因此,一(yī)個(gè)過大或過小的值是否是真的異常值,需要首先進行判斷,判别的方法是進行檢驗。如(rú)果數據服從正态分(fēn)布,檢驗的方法有奈爾檢驗、格拉布斯檢驗等。
當正态總體(tǐ)的方差已知時(shí),采用奈爾檢驗,奈爾檢驗的統計量為(wèi)

當顯着性水平和樣本的數據個(gè)數已知時(shí),通過查表可以得到臨界值,當最大或最小對應的統計量大于臨界值時(shí),認為(wèi)該值異常,剔除該值。剔除異常值後,需要對剩下(xià)的數據重新(xīn)進行異常值檢驗,并重複以上(shàng)過程,直到沒有數據能(néng)被剔除為(wèi)止。
2、逆,适度指标處理(lǐ)

3、數據的标準化(huà)
對于具有不同級或不同單位的數據,在進行數據統計之前,往往需要進行處理(lǐ),使數據在更平等的條件下(xià)進行分(fēn)析。目前進行數據處理(lǐ)的方法大緻有3種,既标準化(huà)、極差标準化(huà)和正規化(huà)。
(1)标準化(huà)

二、景氣指數模型構建
1、選擇因子(zǐ)分(fēn)析法的原因
要正确反映某一(yī)行業或某一(yī)企業是否景氣,必須從不同的方面進行描述和分(fēn)析,在衆多的分(fēn)析法中因子(zǐ)分(fēn)析法有其獨到之處,它可以從宗錯複雜關(guān)系的經濟現(xiàn)象中找出少數幾個(gè)主因子(zǐ),每個(gè)主因子(zǐ)代表經濟變量之間(jiān)相互依賴的一(yī)種經濟作(zuò)用,抓住這(zhè)些(xiē)因子(zǐ)就(jiù)可以幫助我們對複雜的經濟問題進行分(fēn)析和解釋。因此,本文景氣指數的構建采用了(le)因子(zǐ)分(fēn)析法。
2、因子(zǐ)模型分(fēn)析法則
因子(zǐ)模型法基本原理(lǐ)及因子(zǐ)分(fēn)析法的基本思路(lù)是根據相關(guān)性大小把變量分(fēn)組,使組内相關(guān)性較高,組間(jiān)相關(guān)性較低(dī),每組變量代表一(yī)個(gè)基本結構,這(zhè)個(gè)基本結構叫公共因子(zǐ)。對于由多指标構成的某問題可試圖用最少個(gè)數的公共因子(zǐ)的線性函數與特殊因子(zǐ)之和來(lái)表示每一(yī)個(gè)分(fēn)量,并且要求各因子(zǐ)之間(jiān)相互獨立。這(zhè)樣不僅消除了(le)指标間(jiān)信息重疊,而且還起到了(le)降維的作(zuò)用,便于抓住事(shì)物的主要矛盾。
因子(zǐ)分(fēn)析模型如(rú)下(xià):
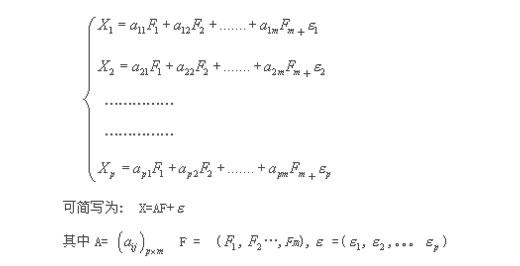

求解因子(zǐ)模型的關(guān)鍵是求解因子(zǐ)負荷系數。求解因子(zǐ)負荷系數的方法有主成份分(fēn)析法、廣義最小平方法、極大似然法等,最常用的是主成份分(fēn)析法。
以上(shàng)是因子(zǐ)分(fēn)析法的一(yī)般原理(lǐ)和基本的分(fēn)析計算(suàn)步驟。在實際運作(zuò)過程和實務(wù)中,可利用SPSS、SAS等多變量經濟數據分(fēn)析軟件進行非常方便地操作(zuò)。
3、指标權重的确定
指标權重的确定的方法有主觀賦權法,客觀賦權法。主觀賦權法是根據各指标的實際觀察值所提供的信息大小來(lái)确定各指标的權重,一(yī)般使用于綜合評價指标數目較少,各指标對綜合評價值确定的重要性易于區别并且各指标間(jiān)相關(guān)性較小的情況下(xià)。當指标的重要性很難區分(fēn)時(shí)可采用客觀賦權法,即利用各指标實際觀察值所提供的信息量大小來(lái)确定指标權重,提供信息越多的指标賦權重就(jiù)越大, 反之所賦權就(jiù)越小。本文采用客觀賦權法——巴特萊特法來(lái)估計因子(zǐ)得分(fēn)。
4、景氣指數的生(shēng)成:

作(zuò)者介紹:河(hé)南(nán)君友商(shāng)務(wù)咨詢有限公司研究員(yuán)