顧客滿意度模型估計的PLS與LISREL
2005/1/2 10:15:03
作(zuò)者:羅春财
顧客滿意度模型是一(yī)個(gè)多方程的因果關(guān)系系統——結構方程模型(SEM,Structural Equation Model),有多個(gè)因變量,是一(yī)個(gè)原因和結果關(guān)系的網,模型必須要按照這(zhè)些(xiē)關(guān)系進行估計。模型中包括質量感知、顧客滿意度、顧客忠誠度和企業形象等隐變量,這(zhè)些(xiē)隐變量隻能(néng)通過多個(gè)具體(tǐ)測量變量來(lái)間(jiān)接衡量。模型中允許自變量和因變量含有測量誤差,還必須要計算(suàn)出來(lái)隐變量的表現(xiàn)得分(fēn)(例如(rú)通過多個(gè)測量變量的加權指數)。
以ACSI模型為(wèi)例,它就(jiù)是一(yī)個(gè)結構方程模型,包括結構方程(隐變量之間(jiān)關(guān)系的方程)和測量方程(隐變量和測量變量之間(jiān)關(guān)系的方程) 。要對結構方程模型進行參數估計,目前最經常使用的兩種方法是PLS(Partial Least Square)方法和LISREL(LInear Structural RELationships)方法。這(zhè)兩種方法既有相同之處,也(yě)有許多不同之處。本文主要討(tǎo)論兩種方法的算(suàn)法,以及他們之間(jiān)的聯系與區别,并根據實證案例,提出我國在構建顧客滿意度模型過程中使用的方法。
一(yī)、PLS和LISREL方法
PLS(Wald,1982)是将主成分(fēn)分(fēn)析與多元回歸結合起來(lái)的叠代估計,是一(yī)種因果建模的方法。瑞典、美國和歐盟模型都使用這(zhè)種方法進行估計。在ACSI模型估計中 ,該方法對不同隐變量的測量變量子(zǐ)集抽取主成分(fēn),放(fàng)在回歸模型系統中使用,然後調整主成分(fēn)權數,以最大化(huà)模型的預測能(néng)力。PLS方法的具體(tǐ)步驟如(rú)下(xià)所示。
步驟1:用叠代方法估計權重和隐變量得分(fēn)。從④開始,重複①—④直至收斂。

步驟2:估計路(lù)徑系數和載荷系數。
步驟3:估計位置參數。
PLS方法是“偏”LS,因為(wèi)估計的每一(yī)步都在給定其他參數條件下(xià),對某個(gè)參數子(zǐ)集的殘差方差進行最小化(huà)。雖然在收斂的極限,所有殘差方差聯合的進行最小化(huà),但(dàn)PLS方法仍然是“偏”LS,因為(wèi)沒有對總體(tǐ)殘差方差或其他總體(tǐ)最優标準嚴格的進行最小化(huà)。
LISREL(Joreskog,1970)方法通過拟合模型估計協方差 與樣本協方差(S)來(lái)估計模型參數,也(yě)稱為(wèi)協方差建模方法。具體(tǐ)來(lái)說(shuō),就(jiù)是使用極大似然(Maximum Likelihood,ML)、非加權最小二乘(Unweighted Least Squares,ULS)、廣義最小二乘(Generalized LeastSquares,GLS)或其他方法 ,構造一(yī)個(gè)模型估計協方差與樣本協方差的拟合函數,然後通過叠代方法,得到使拟合函數值最優的參數估計。例如(rú),采用ML方法的拟合函數的形式為(wèi):
LISREL中的步驟與PLS相反:先估計參數,然後如(rú)果需要,再考慮所有結構信息,對所有觀測變量作(zuò)回歸,“估計”隐變量。LISREL 軟件可以進行模型的識别,對所有估計參數的标準誤進行檢驗,并對模型拟合程度進行檢驗。
為(wèi)了(le)得到最優估計,ML方法的計算(suàn)量很大。最麻煩的是信息矩陣(也(yě)稱為(wèi)Hessian矩陣,即似然函數對模型中任意兩個(gè)參數的二階偏微分(fēn)矩陣)。如(rú)果模型可識别,Hessian矩陣必須是正定的。
二、兩種方法的聯系與區别
上(shàng)面簡要介紹的PLS和LISREL方法,既有相似之處,也(yě)有不同。它們的第一(yī)個(gè)相似點是都采用箭頭示意圖作(zuò)為(wèi)模型的圖形表示。第二個(gè)相似點是在每個(gè)區組(block),都假設測量變量與隐變量和誤差項為(wèi)線性關(guān)系,即y=Λyη+ε x=Λxξ+δ (6)
第三個(gè)相似點是路(lù)徑關(guān)系(PLS中稱為(wèi)内部關(guān)系)的表達形式一(yī)樣,η=Βη+Гξ+ζ 或 (I-Β)η=Гξ+ζ。 (7)
第四個(gè)相似點是對每個(gè)内生(shēng)變量區組,都給出顯變量y的因果-預測關(guān)系,即用隐變量路(lù)徑關(guān)系中的解釋變量來(lái)表示y,y=Λy(Βη+Гξ)+ε+Λyζ (8)
PLS和LISREL也(yě)有許多不同之處。它們的區别類似主成分(fēn)分(fēn)析與因子(zǐ)分(fēn)析的區别。PLS是從主成分(fēn)分(fēn)析發展而來(lái)的,LISREL是從因子(zǐ)分(fēn)析發展而來(lái)的。
第一(yī),分(fēn)布假設不同。PLS為(wèi)了(le)處理(lǐ)缺乏理(lǐ)論知識的複雜問題,采取“軟”方法,避免LISREL模型嚴格的“硬”假設。這(zhè)樣,不論模型大小,PLS方法都可以得到“瞬時(shí)估計(instant estimation)”,并得到漸進正确的估計,即PLS方法沒有分(fēn)布要求,而LISREL方法假設顯變量的聯合分(fēn)布為(wèi)多元正态。
第二,目标不同。PLS方法的目标是根據區組結構(6)、内部關(guān)系(7)和因果預測關(guān)系(8)進行預測,而LISREL方法研究的目标是矩陣Σ的結構。
第三,準确性取向不同。PLS估計在樣本量很大和每個(gè)隐變量的顯變量很多時(shí),是一(yī)緻(consistency)和基本一(yī)緻(consistency at large)的,但(dàn)LISREL估計在大樣本時(shí)是最優的(置信區間(jiān)漸近最小)。最優性包括一(yī)緻性,但(dàn)一(yī)緻性不包括最優性。因此,PLS和LISREL對同一(yī)參數的估計都在一(yī)緻性的範圍内。兩種估計的差别不可能(néng)、也(yě)不應該很大。
第四,假設檢驗不同。PLS方法采用Stone(1974)和Geisser(1974)的交互驗證(cross-validation)方法檢驗,考察因果預測關(guān)系(8)。LISREL方法一(yī)般使用似然比檢驗,考察觀測矩陣S和理(lǐ)論矩陣Σ的拟合程度。
第五,估計順序不同。PLS方法通過逼近,先将每個(gè)區組的隐變量的估計得分(fēn)表示為(wèi)測量變量的加權合計, ,然後通過一(yī)系列權重關(guān)系的叠代,得到權重的估計。LISREL方法先估計載荷Λy和Λx,在這(zhè)個(gè)過程中消去隐變量,然後通過對測量變量的多元OLS回歸,估計隐變量的樣本值(因子(zǐ)得分(fēn))。
第六,對方程中變量間(jiān)的關(guān)系理(lǐ)解不同。PLS方法将系統部分(fēn)(6)和(7)定義為(wèi)給定解釋變量值時(shí)的條件期望,作(zuò)為(wèi)變量間(jiān)的因果預測關(guān)系。因此,對于(6),PLS方法假設,
E(y/η)=Λyη E(x/ξ)=Λxξ (9)
對于(7),PLS方法假設,
E(η/η,ξ)=Bη+Гξ (10)
而LISREL方法将結構關(guān)系(6)和(7)定義為(wèi)具有誤差的确定性“方程”,即變量間(jiān)是具有誤差的确定性關(guān)系。
第七,模型的識别不同。PLS方法中,雖然隐變量的估計是逼近得到的,但(dàn)由于估計是顯式的(explicit),因此PLS方法中沒有識别問題。LISREL方法中,矩陣Σ的結構是由區組結構(6)決定的,(6)又受到路(lù)徑關(guān)系(7)的限制,LISREL方法有可能(néng)不能(néng)識别模型。因此,LISREL估計的第一(yī)個(gè)階段就(jiù)是考察模型的可識别性。如(rú)果不能(néng)識别,模型中必須包括一(yī)些(xiē)參數假設(reparameterization assumption)。
最後,PLS方法中,還可以選擇三種加權關(guān)系,取決于更關(guān)注(6)、(7)還是(8)的操作(zuò)性。權重關(guān)系模式A和模式B分(fēn)别使用簡單OLS回歸和多元OLS回歸,模式C是二者的結合。在PLS模型的圖形中,顯變量與其隐變量之間(jiān)的箭頭指向表明了(le)選擇的估計模式。
三、PLS和LISREL的适用條件
人(rén)們在兩種方法的選擇上(shàng)一(yī)直存在分(fēn)歧,由以上(shàng)比較可見,PLS适用于以下(xià)情況:
1.研究者更加關(guān)注通過測量變量對隐變量的預測,勝于關(guān)注滿意度模型的參數估計值大小,因為(wèi)PLS的估計量是有偏的,但(dàn)可以根據測量變量得到隐變量的最優預測 。
2.适用于數據有偏分(fēn)布的情況,因為(wèi)PLS使用非參數推斷方法(例如(rú)Jackknife),不需要對數據進行嚴格假定;而LISREL假設觀測是獨立的,且服從多元正态分(fēn)布。
3.适用于關(guān)注隐變量得分(fēn)的情況,因為(wèi)PLS在參數估計過程中就(jiù)計算(suàn)隐變量得分(fēn),可以得到确定的計算(suàn)結果。而LISREL在進行參數估計之後,再采用某個(gè)目标函數計算(suàn)隐變量得分(fēn),計算(suàn)結果因目标函數選擇不同而不同。
4.适用于小樣本滿意度研究 ,因為(wèi)PLS是一(yī)種有限信息估計方法,所需要的樣本量比完全信息估計方法LISREL小得多。
5. 适用于較大、較複雜的結構方程模型,因為(wèi)PLS收斂速度非常快(kuài),計算(suàn)效率比LISREL更高 。但(dàn)對于不太複雜的顧客滿意度模型,計算(suàn)時(shí)間(jiān)的優勢不明顯。
LISREL适用的情況不同:
1.研究者更加關(guān)注滿意度模型的參數估計值大小,即測量變量對隐變量的影響和測量變量的效度,而不是純粹的預測應用;而且,隻有當模型的參數估計無偏時(shí),才能(néng)驗證測量變量的效度,因此PLS不能(néng)對此進行驗證,因為(wèi)PLS估計的隐變量路(lù)徑系數有低(dī)估,不能(néng)揭示隐變量之間(jiān)的關(guān)系(Dijkstra, 1983);PLS的隐變量載荷的參數估計易于趨同,且有高估偏差。
2.适用于不同的樣本間(jiān)參數估計比較的情況,因為(wèi)LISREL可以提供 檢驗,而PLS得到的權重、載荷和隐變量得分(fēn)在不同樣本間(jiān)的可比較性是一(yī)個(gè)值得懷疑的問題。
同時(shí),随着LISREL的發展和完善,也(yě)可以利用PLS的思想來(lái)彌補自身(shēn)的缺陷:
3.盡管LISREL中ML估計的有效性、标準誤差和檢驗統計量的正确性需要數據正态和獨立的假設,但(dàn)隻要滿足某些(xiē)條件,這(zhè)些(xiē)特性并不會受到非正态的影響(Satorra,1990)。此外,LISREL也(yě)可以像PLS一(yī)樣使用非參數重抽樣方法(例如(rú)bootstrap)進行統計推斷。
4.LISREL中的ML估計,即使分(fēn)布假設不成立也(yě)非常穩健,可以得到總體(tǐ)參數的一(yī)緻估計。然後基于這(zhè)些(xiē)參數,采用幾種目标函數計算(suàn)隐變量得分(fēn)。這(zhè)些(xiē)目标函數不同于PLS目标函數,但(dàn)這(zhè)并不能(néng)說(shuō)明得分(fēn)是不确定的。而PLS通過最大化(huà)測量變量的可靠性估計和隐變量回歸的R2來(lái)計算(suàn)隐變量得分(fēn),導緻PLS參數估計有偏 ,使隐變量得分(fēn)的價值大打折扣。
實際上(shàng),兩種方法各有千秋,分(fēn)别适用于不同的情況。從根本上(shàng)說(shuō),由于算(suàn)法的不同,PLS對測量變量協方差矩陣的對角元素的拟合較好(hǎo)(hǎo),适用于對數據點的分(fēn)析,預測的準确程度較高;LISREL對測量變量協方差矩陣的非對角元素的拟合較好(hǎo)(hǎo),适用于對協方差結構的分(fēn)析,參數估計更加準确。兩種方法的選擇取決于研究的目的。當研究目的是理(lǐ)論檢驗且先驗理(lǐ)論知識充足時(shí),更宜采用LISREL;當研究目的是因果預測應用,且理(lǐ)論知識非常缺乏時(shí),則PLS更加适合。因此,從實用的角度可以說(shuō),ML和PLS方法是互補的,而不是互斥的。
四、我國構建顧客滿意度模型時(shí)估計方法的選擇
對于我國顧客滿意度模型估計方法的選擇,主要應該在我國不同行業的不同公司進行試算(suàn),也(yě)可以采取模拟數據進行研究,參照國外的研究結果,對我國的實證結論進行PLS和LISREL的比較。
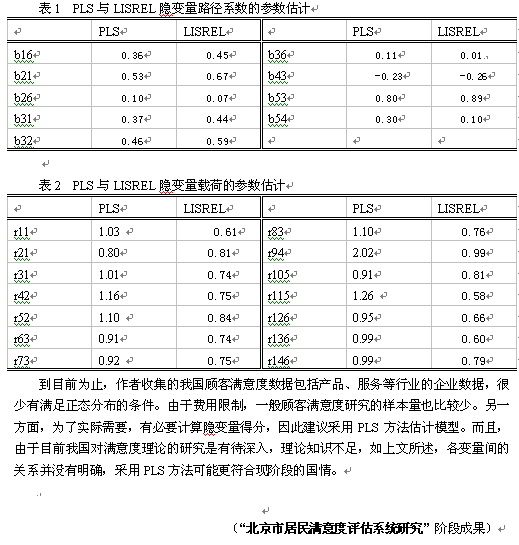
作(zuò)者對某服務(wù)行業公司的滿意度數據進行測算(suàn) ,兩種方法得到的結果進行比較,結論與前文類似。PLS估計的隐變量路(lù)徑系數有低(dī)估,PLS的隐變量載荷的參數估計易于趨同,且有高估偏差,結果如(rú)下(xià)表所示 :
作(zuò)者介紹:河(hé)南(nán)君友商(shāng)務(wù)咨詢有限公司行業研究部經理(lǐ)